PENGERTIAN
Crawling
Web Crawler adalah suatu program atau script otomat yang relatif simple, yang dengan metode tertentu melakukan scan atau “crawl” ke semua halaman-halaman internet untuk membuat index dari data yang dicarinya. Nama lain untuk web crawl adalah web spider, web robot, bot, crawl dan automatic indexer.Proses crawling dalam suatu website dimulai dari mendata seluruh url dari website, menelusurinya satu-persatu, kemudian memasukkannya dalam daftar halaman pada indeks search engine, sehingga setiap kali ada perubahan pada website, akan terupdate secara otomatis.
Web crawler dirancang secara algoritmik untuk mencapai kedalaman maksimum halaman dan merayapnya secara iteratif, menggali setiap data yang ada di internet seperti seperti : meta data, keyword, dan lain sebagainya. Kemudian web crawler atau si (spider man) ini akan meng index seluruh data kita ke dalam data base search engine. Sampai pada akhirnya halaman website akan ditampilkan di SERP (search engine rage page).
Banyak situs menggunakan web crawling namun yang paling canggih dan paling populer saat ini adalah mesin pencari seperti Google dan Bing yang menjaga hasil pencarian mereka tetap segar dengan spidering sebagai cara menyediakan data terbaru.
Scraping
Data scrapping adalah sebuah teknik untuk mengambil data yang bisa didapatkan dari website, sosial media, informasi dari mesin local, database, dan lainnya. Data yang telah di scrapping akan dikumpulkan jadi satu di dalam sebuah berkas/file, bisa jadi file excel atau json.Biasanya teknik scraping diimplementasikan pada sebuah bot agar bisa membuat proses yang harusnya dilakukan secara manual menjadi otomatis. Ketika kita menjumpai sebuah situs yang membatasi kuota API (Application Programming Interface) atau bahkan tidak menyediakan sama sekali, maka perayapan web akan sangat dibutuhkan sebagai langkah pengambilan data.
Web scraping dilakukan dengan menggunakan web scraper, bot, web spider, atau web crawler. Web scraper sendiri adalah program yang masuk ke halaman website, download kontennya, mengekstrak data dari konten, dan menyimpan data ke satu file atau database. Teknik ini biasa digunakan untuk menganalisa sebuah kejadian yang sedang ramai di dunia internet. Atau bisa juga digunakan untuk aplikasi berita seperti BaBe, Kurio, Opera News, Line Today untuk mengumpulkan banyak berita yang nantinya akan diambil datanya dan kemudian diolah kembali.
Ada banyak alasan mengapa web scraping semakin diperlukan di zaman sekarang. Dengan semakin berkembangnya big data, jumlah data yang tersedia sudah tidak terhitung lagi. Web scraping bisa membantu untuk mengumpulkan data dengan lebih cepat dan melakukan automation.
TOOLS
Crawling
a. Visual SEO Studio
Menawarkan saran SEO komprehensif, kontrol penuh atas XML Sitemap pengguna dan mesin kueri berorientasi SEO yang kuat.

b. WildShark SEO Spider Tool
Web crawler standar dan memberi user akses ke tag H seperti biasa, tag judul, dan tag ALT, menemukan tautan rusak dan menduplikasi tag meta. User harus mengisi formulir sebelum dapat mengunduh dan berlangganan basis data buletin mereka. Hanya tersedia untuk Windows.

c. CocoScan
CocoScan adalah alat pemindaian SEO sederhana yang menganalisis situs web dan menemukan semua faktor yang memblokir indeksasi halaman web.
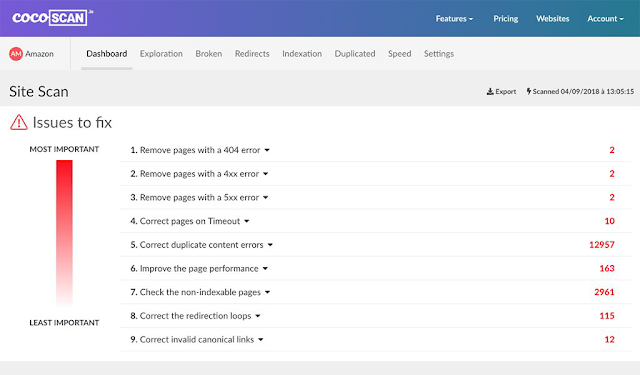
CocoScan adalah alat pemindaian SEO sederhana yang menganalisis situs web dan menemukan semua faktor yang memblokir indeksasi halaman web.

d. Screaming Frog SEO Spider
Screaming Frog SEO Spider adalah web clrawler yang memungkinkan untuk melakukan crawl atau merayapi URL situs web dan mengambil elemen penting di lokasi untuk menganalisis SEO di tempat.

e. Raptorbot
(Raptorbot) berbasis cloud, artinya dapat merayapi jutaan halaman web dengan cepat dan efisien tanpa perlu menginstal perangkat lunak apa pun. Yang di butuhkan untuk memulai adalah browser web dan akses ke internet.

Screaming Frog SEO Spider adalah web clrawler yang memungkinkan untuk melakukan crawl atau merayapi URL situs web dan mengambil elemen penting di lokasi untuk menganalisis SEO di tempat.

e. Raptorbot
(Raptorbot) berbasis cloud, artinya dapat merayapi jutaan halaman web dengan cepat dan efisien tanpa perlu menginstal perangkat lunak apa pun. Yang di butuhkan untuk memulai adalah browser web dan akses ke internet.

Scraping
a. Import.ioImport.io menawarkan pembangun untuk membentuk dataset sendiri dengan hanya mengimpor data dari halaman web tertentu dan mengekspor data ke CSV. Scraping dapat dilakukan dengan mudah dalam hitungan menit tanpa menulis satu baris kode dan membangun 1000 + API berdasarkan kebutuhan.

b. Webhose.io
Webhose.io menyediakan akses langsung ke real-time dan data terstruktur dari ribuan sumber online. Web scraper mendukung penggalian data web di lebih dari 240 bahasa dan menyimpan data output dalam berbagai format termasuk XML, JSON dan RSS.

c. Data-miner.io
Adalah alat ekstraksi data yang memungkinkan pengguna melakukan scraping halaman web HTML apa pun. Anda dapat mengekstrak tabel dan daftar dari halaman mana saja dan mengunggahnya ke Google Sheets atau Microsoft Excel. Dengan Scraper Anda dapat mengekspor halaman web ke file XLS, CSV, XLSX atau TSV (.xls .csv .xlsx .tsv)

d. Dexi.io
Dexi.io adalah aplikasi scraping berbasis website. Artinya, tidak perlu download aplikasi untuk bisa mulai scraping web. Kamu bisa menyiapkan crawlers dan fetch data secara real-time.
Dexi.io juga memiliki fitur dimana kamu bisa menyimpan data yang telah di-scrape pada cloud seperti Box.net dan Google Drive. Penyimpanan juga bisa dilakukan secara konvensional dengan ekspor menjadi file JSON atau CSV.

e. ParseHub
ParseHub adalah aplikasi web scraping yang mendukung ekstraksi data kompleks dari website yang menggunakan AJAX, JavaScript, redirects, dan cookies. Dilengkapi dengan teknologi machine learning yang bisa membaca dan menganalisis dokumen pada website untuk menghasilkan data yang relevan.

Webhose.io menyediakan akses langsung ke real-time dan data terstruktur dari ribuan sumber online. Web scraper mendukung penggalian data web di lebih dari 240 bahasa dan menyimpan data output dalam berbagai format termasuk XML, JSON dan RSS.

c. Data-miner.io
Adalah alat ekstraksi data yang memungkinkan pengguna melakukan scraping halaman web HTML apa pun. Anda dapat mengekstrak tabel dan daftar dari halaman mana saja dan mengunggahnya ke Google Sheets atau Microsoft Excel. Dengan Scraper Anda dapat mengekspor halaman web ke file XLS, CSV, XLSX atau TSV (.xls .csv .xlsx .tsv)

d. Dexi.io
Dexi.io adalah aplikasi scraping berbasis website. Artinya, tidak perlu download aplikasi untuk bisa mulai scraping web. Kamu bisa menyiapkan crawlers dan fetch data secara real-time.
Dexi.io juga memiliki fitur dimana kamu bisa menyimpan data yang telah di-scrape pada cloud seperti Box.net dan Google Drive. Penyimpanan juga bisa dilakukan secara konvensional dengan ekspor menjadi file JSON atau CSV.

e. ParseHub
ParseHub adalah aplikasi web scraping yang mendukung ekstraksi data kompleks dari website yang menggunakan AJAX, JavaScript, redirects, dan cookies. Dilengkapi dengan teknologi machine learning yang bisa membaca dan menganalisis dokumen pada website untuk menghasilkan data yang relevan.

PERCOBAAN (Study Kasus : kumparan.com)
Crawling
Melakukan web crawling pada situs kumparan.com menggunakan Raptorbot1. Kunjungi situs https://tools.raptor-dmt.com/https://tools.raptor-dmt.com/ dan lakukan registrasi akun
2. Buat project baru dan isikan data yang dibutuhkan. Kemudian klik Start Crawling.

3. Tunggu proses crawling hingga selesai

4. Klik Reporting untuk melihat hasilnya

5. Klik export untuk mengekspor hasil laporannya

6. Pilih data yang ingin di export (misalnya : SEO Exel Report), klik Build Report, tunggu hingga selesai, kemudian download

7. Berikut adalah hasil dari web crawling kumparan.com yang kemudian bisa digunakan untuk melakukan analisis lebih lanjut.

Scraping
Contoh penggunaan teknik Data Scrapping untuk mengumpulkan berita yang sedang trending, bersumber dari website berita kumparan.com1. Memasang Ekstensi Data Scrapping dari data-miner.io

2. Membuka website yang akan diambil datanya, disini kami mengambil data dari kumparan.com/trending

3. Menjalankan extension Data Scrapper untuk pengambilan data dari website kumparan. Metode yang digunakan adalah dengan mencari sebuah elemen dan class pada halaman HTML yang mengacu pada data yang akan dicari. Semisal data untuk judul artikel berada di elemen H1 dengan class title, maka elemen tersebutlah yang akan discrapping dan akan diambil valuenya. Contoh ada dibawah.

4. Disini kami akan mengambil data berupa judul artikel, sumber berita, dan URL berita. Dan hasil pengambilan data dari website kumparan.com adalah sebagai berikut.

5. Data tersebut dapat di export dan menjadi file excel

